

Rapid Elasticity in Cloud Computing: What It Is, Why It Matters, and How to Actually Use It
Harash Jindal
Apr 1, 2026

Most businesses don’t need 24/7 cloud capacity. They need it during product launches, quarter-end reporting, holiday rushes, or a sudden spike in users. The problem? Legacy infrastructure wasn’t built for “sometimes.” You either overbuy and waste money or underbuy and get burned during the exact moments that matter most.
That’s the gap that rapid elasticity in cloud computing was designed to close.
This isn’t just a technical capability. For enterprise leaders making real infrastructure decisions, understanding rapid elasticity – and deploying it intelligently – is increasingly the difference between a cloud investment that delivers ROI and one that quietly bleeds budget.
What Is Rapid Elasticity in Cloud Computing?
Rapid elasticity is one of the five essential characteristics of cloud computing, as formally defined by the National Institute of Standards and Technology (NIST). NIST describes it as the ability to provision and release capabilities “rapidly and elastically” – in some cases automatically – to scale outward and inward in response to demand.
In plain terms: your infrastructure grows when it needs to, and shrinks back down when it doesn’t. And ideally, none of this requires someone manually spinning up servers at 2 a.m.
The distinction that trips people up is rapid elasticity vs. scalability. Scalability is long-term capacity planning – you’re building for future growth, and the resources you add typically stay. Rapid elasticity is about short-term, dynamic response.
To understand how elasticity fits into the broader cloud computing picture, it helps to view it as part of the on-demand resource-pooling model that defines modern cloud infrastructure.
How It Actually Works
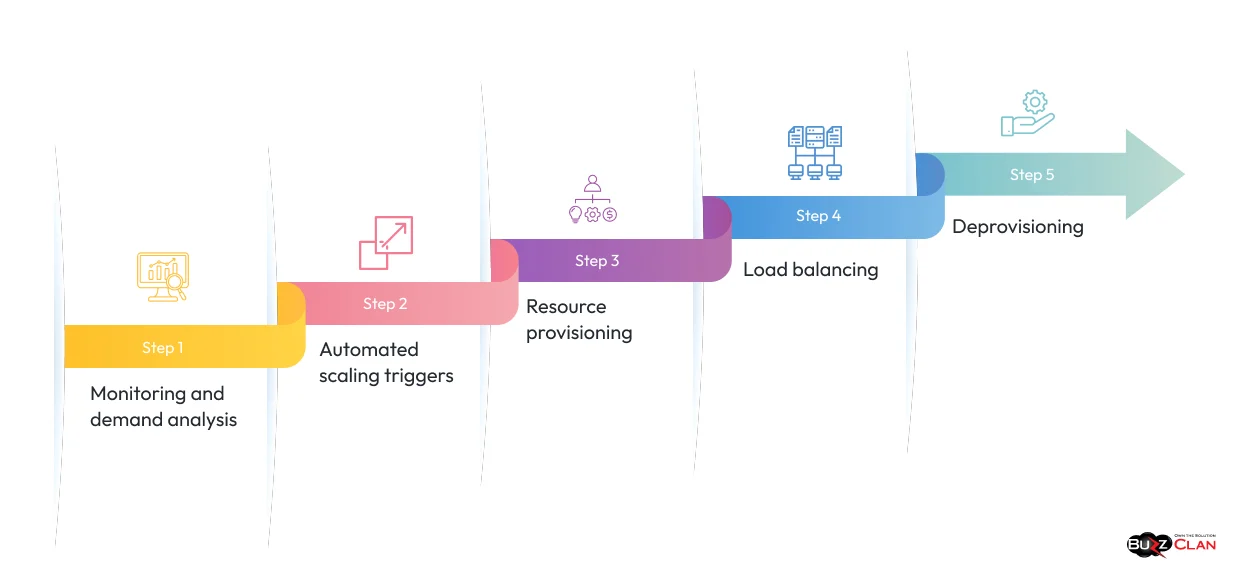
Under the hood, rapid elasticity relies on a combination of automated monitoring, predefined triggers, and shared resource pools. Here’s the flow:
Monitoring and demand analysis
The cloud environment continuously watches CPU usage, memory consumption, network traffic, and application load. This isn’t passive logging. It’s active tracking that feeds directly into scaling decisions.
Automated scaling triggers
When metrics hit predefined thresholds (say, CPU stays above 80% for 3 minutes), the system fires off a scaling event without waiting for a human to notice.
Resource provisioning
New virtual machines, containers, or storage units are assigned from the provider’s shared pool. Public cloud providers like AWS, Azure, and Google Cloud can provision these resources in seconds to minutes.
Load balancing
Traffic gets redistributed across the expanded resource pool, preventing any single instance from becoming a bottleneck.
Deprovisioning
Once demand normalizes, those extra resources get released. You stop paying for them. The system returns to its efficient baseline.
This cycle repeats continuously. For a retail company managing seasonal demand or a SaaS platform handling uneven user behavior, this kind of automated responsiveness is a genuine operational advantage.
There are two flavors of elastic scaling worth knowing: vertical scaling (adding more power to existing instances – more CPU, more RAM) and horizontal scaling (adding more instances). Most enterprise architectures lean on horizontal scaling for elasticity because it distributes load and avoids single points of failure.
Ready to Build Infrastructure That Scales With Your Business?
BuzzClan helps enterprise teams design and implement elastic cloud architectures.
The Business Case: What Rapid Elasticity Means for Enterprise Operations
Let’s be direct about why this matters beyond the technical specs.
Cost discipline without performance sacrifice
Traditional infrastructure forces a painful tradeoff. You buy enough capacity to handle peak load, which means you’re massively over-provisioned most of the time. Cloud cost optimization research consistently shows that enterprises waste 20-35% of their cloud spend on idle resources. Rapid elasticity breaks this pattern. You pay for actual usage, not theoretical peaks.
Operational resilience during demand spikes
A spike that crashes an under-provisioned system doesn’t just hurt performance. It hurts revenue and trust. The serverless computing market – built on elastic infrastructure principles – is projected to reach $36.8 billion by 2028, which tells you something about where enterprise demand is heading. Businesses are voting with their spending on dynamic, event-driven infrastructure.
Developer velocity
Engineering teams waste significant time managing infrastructure that doesn’t need to be managed. When rapid elasticity handles scaling automatically, developers can focus on building the product instead of firefighting capacity issues. Cloud management best practices consistently point to automation as a key lever for reducing operational overhead and improving release cadence.
Competitive agility
Markets move fast. A business that can scale infrastructure to support a new product launch in hours rather than weeks has a meaningful advantage. This isn’t abstract – it translates directly to time-to-market.
Rapid Elasticity in Practice: Real-World Examples
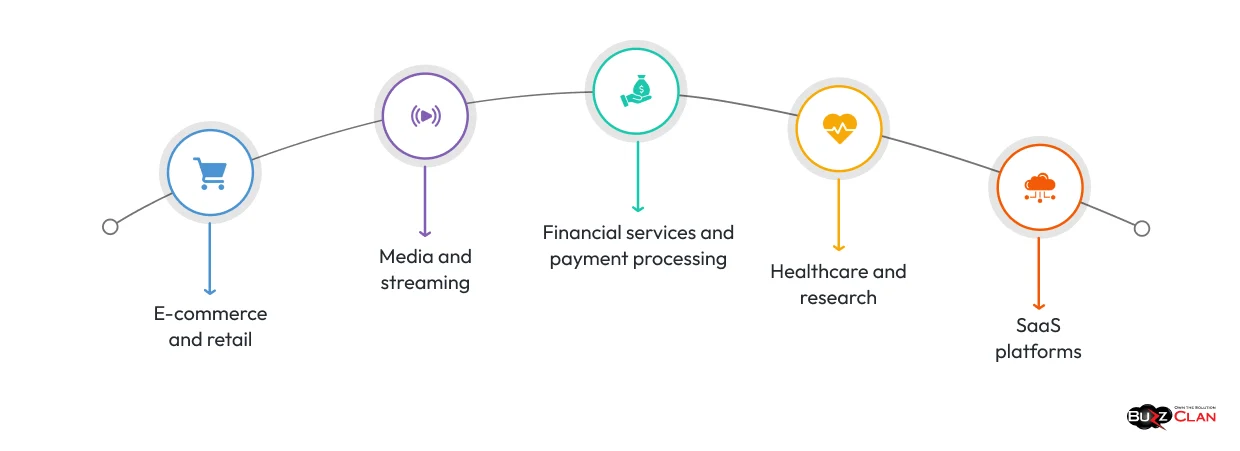
Understanding the concept is one thing. Seeing where it actually applies helps translate theory into decisions.
E-commerce and retail
Amazon, major retailers, and direct-to-consumer brands face demand that can spike 10x or more during sales events. Without elasticity, you’re either overspending on standby capacity or risking outages during the moments that drive the most revenue.
Media and streaming
When a new series drops or a live event kicks off, streaming platforms can see dramatic spikes in concurrent users. Elastic scaling provisions additional compute resources instantly, keeping playback smooth while costs track actual viewership.
Financial services and payment processing
Payment gateways handle dramatically higher transaction volumes during holidays, tax season, and promotional periods. Rapid elasticity allows these systems to scale compute without touching the underlying architecture.
Healthcare and research
Data-intensive workloads like genomic sequencing, imaging analysis, and population health analytics have unpredictable compute demands. Elastic infrastructure allows these bursts without permanent over-provisioning.
SaaS platforms
Product launches, marketing campaigns, and viral growth events can cause sudden onboarding spikes. Elastic cloud infrastructure ensures new users get a consistent experience regardless of when they show up.
Rapid Elasticity vs. Scalability
| Aspect | Scalability | Rapid Elasticity |
|---|---|---|
| Definition | Planned increase in capacity to handle expected growth | Automatic adjustment of resources based on real-time demand |
| Nature | Proactive and strategic | Reactive and dynamic |
| Duration | Long-term (resources remain after provisioning) | Short-term (resources scale up and down as needed) |
| Purpose | Supports steady, predictable growth | Handles sudden spikes or drops in demand |
| Example | Building a larger warehouse for future inventory | Renting extra warehouse space during peak season |
| Resource Behavior | Resources are added and retained | Resources expand and contract automatically |
| Cost Impact | Can lead to higher fixed costs if overestimated | More cost-efficient for variable workloads |
| Use Case | Business expansion, long-term user growth | Traffic spikes, seasonal demand, flash sales |
| Risk if Misused | Overprovisioning or underutilization | Performance issues if not properly configured |
| Best Practice | Plan capacity as part of a strong Cloud Strategy | Combine with elasticity for efficient workload handling |
Challenges Worth Addressing
Rapid elasticity isn’t a “set it and forget it” capability. A few friction points show up regularly in enterprise deployments:
Cost creep from poor configuration
Auto-scaling policies that aren’t tuned correctly can provision resources unnecessarily or fail to deprovision quickly enough. This is one of the most common cloud cost mistakes enterprises make. Predictive analytics and well-defined scaling policies help significantly here.
Cold start latency
Some workloads experience a brief delay when new resources initialize. For most use cases, this is negligible, but for latency-sensitive applications, it warrants attention. Container-based architectures help reduce this gap.
Security posture during dynamic scaling
Dynamic environments create complexity around authentication, access control, and audit trails. As cloud security practices have evolved, this is manageable – but it requires deliberate architecture, not an afterthought.
Legacy application compatibility
Applications built for static infrastructure don’t always behave well in elastic environments. Depending on your current stack, a migration or refactoring may be required before you can fully take advantage of elasticity. Understanding cloud deployment models helps frame the right path forward.
How BuzzClan Approaches Rapid Elasticity for Enterprise Clients
At BuzzClan, cloud work isn’t just about migration – it’s about building infrastructure that performs intelligently under real-world conditions. Rapid elasticity is one of the capabilities we design for from the start, not bolted on afterward.
Our cloud services practice works across AWS, Azure, and Google Cloud to architect auto-scaling environments that match actual business behavior. That means analyzing your workload patterns, defining appropriate scaling policies, integrating with your monitoring stack, and ensuring cost controls are in place before elasticity policies go live.
Where needed, we pair elastic infrastructure design with post-migration optimization – helping clients who’ve already moved to the cloud but haven’t fully activated elastic capabilities. The gap between “we’re on the cloud” and “our infrastructure dynamically responds to demand” is where a significant amount of cloud ROI gets left behind.
We’ve helped organizations in financial services, healthcare, and technology move from flat, over-provisioned environments to elastic architectures that meaningfully reduce idle resource spend while improving performance during peak periods. That dual outcome – lower cost and better performance – is what makes rapid elasticity one of the most impactful levers in enterprise cloud operations.
For a deeper understanding of how elasticity connects to broader cloud design principles, this overview from HPE is worth bookmarking, and Nutanix’s breakdown of cloud elasticity vs. scaling provides useful operational context.
FAQs
Rapid elasticity is a cloud characteristic defined by NIST that refers to the ability to automatically provision and release computing resources in response to changing demand. When workloads spike, resources scale up. When demand drops, they scale back down – and you stop paying for them.
A retail platform that handles normal weekday traffic on a baseline of 10 servers might auto-scale to 80 or 100 servers during a Black Friday event, then automatically scale back once the event ends. No manual intervention, no wasted spend on idle capacity after the event.
In cloud computing, rapid elasticity means the ability to quickly and dynamically adjust infrastructure resources – compute, memory, storage, and networking – in direct response to real-time demand signals. It enables the practical reality of “only pay for what you use.”
Scalability involves planned, long-term capacity additions where resources typically remain once added. Rapid elasticity is short-term and reactive – resources are provisioned on demand and released when no longer needed. Scalability supports planned growth, while elasticity handles unpredictable fluctuations.
Rapid elasticity draws from shared resource pools maintained by cloud providers. For example, when a media platform experiences a surge in viewership for a live event, it pulls compute and bandwidth from the provider’s shared pool. Once the event ends, those resources return to the pool and the billing reflects only the time they were in use.
It refers to the ability to provision and release capabilities elastically – in some cases automatically – so they can scale rapidly outward to handle increased demand and inward when that demand subsides, as defined by NIST.
On-demand self-service allows users to provision resources manually without needing provider interaction. Rapid elasticity enables those resources to scale automatically in response to demand without user intervention. Both are core cloud characteristics but operate at different levels of automation.

Get In Touch
Follow Us








